Hello! My name is Megumiso. and today, in this article, I’m going to make Yukkuri to speak English using machine learning.
Contents
動画
前枠
と言うわけでここからは日本語なので安心してください!
今回は機械学習を使って、みなさんおなじみ日本語ゆっくりボイスで英語をしゃべせらせてみたいと思います。
機械学習を使って喋っている様子は、ぜひ動画でご覧ください!
ブログの方では、今回の機械学習に使用したツールの手順の説明をしていきます。
材料
・GeforceのGPUが入ったパソコン
Radeon製のGPUだと機械学習を使用できないことが多いので、GeforceのGPUが入ったパソコンを使用するのがおすすめです。
一応CPUでもできるけどまあ遅い。
必要なものの構築
Python
機械学習をいえば定番と言われている気がするPythonを導入します。
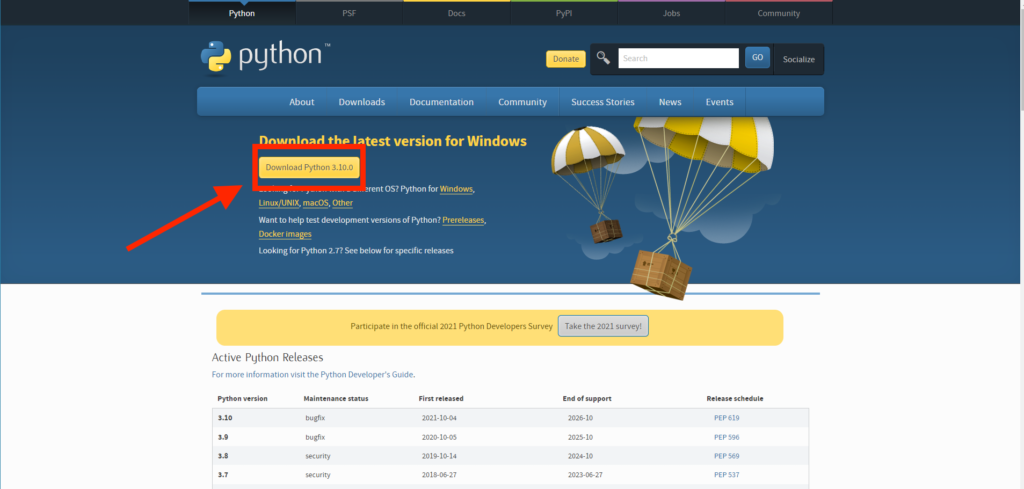
公式サイトのダウンロードページから、Pythonのインストーラーをダウンロードします。
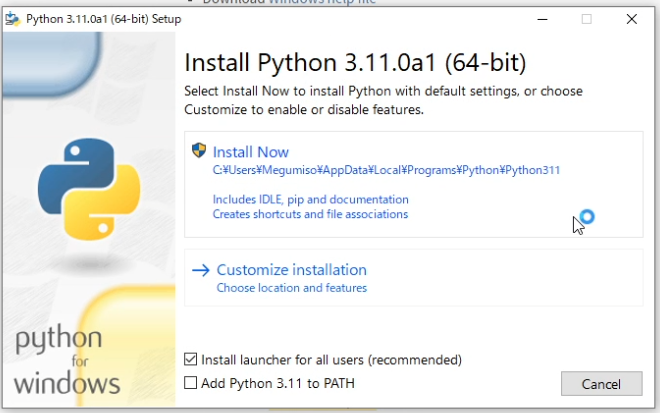
インストーラーで「Install Now」を選択すると、自動的にインストールが開始されます。
特に何もせずにこれでインストールが完了します。
PyTorch
Python用の機械学習ツールです。
公式サイトからダウンロードします。
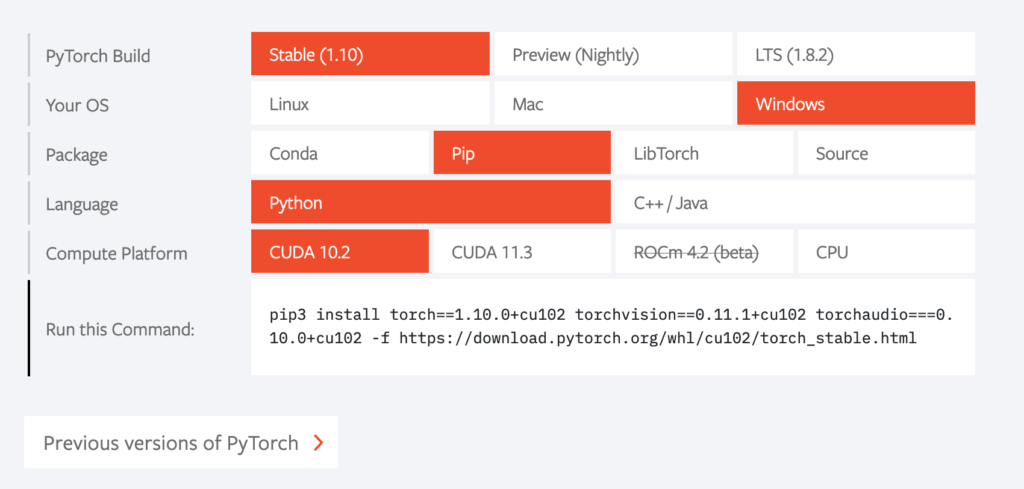
ダウンロードだけで色々種類がありそうですが、Packageは「Pip」を選択して、他はそのままで良いです。
「Run this Command」に表示されている2行程度の長いコマンドを、コマンドプロンプト内で実行します。
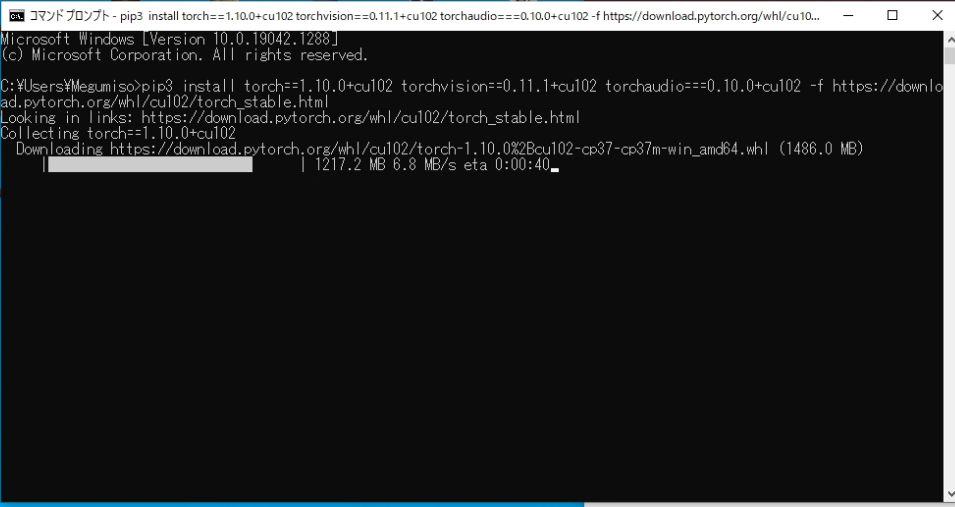
1.5GB程度もあるので、気長に待ちます。インストールも地味に長いです。
ffmpeg
ffmpegのみ、手動でWindowsのPathを変更する動作が含まれます。手順を誤ると、Windowsの動作がおかしくなる場合があるので、気を付けて作業をしてください。
ダウンロード
まずはffmpegの配布をしているサイトに移動します。

「ffmpeg-git-essentials.7z」と書いてあるほうをクリックするとダウンロードが始まります。
7zでダウンロードされるので、7zip等を使用して解凍します。
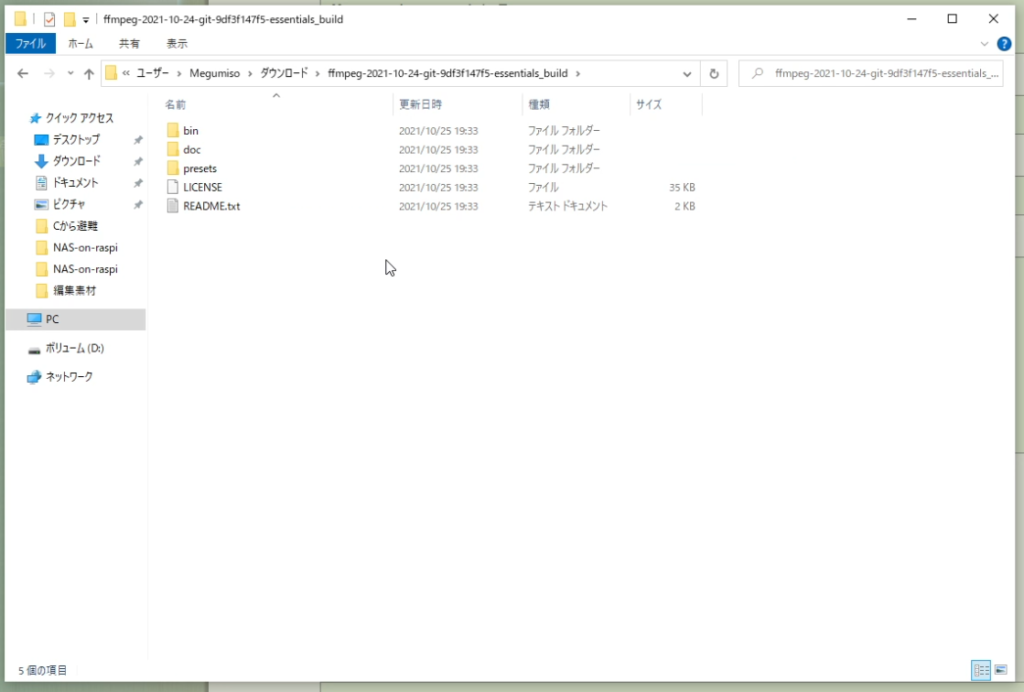
解凍すると、これらのファイルが出現します。
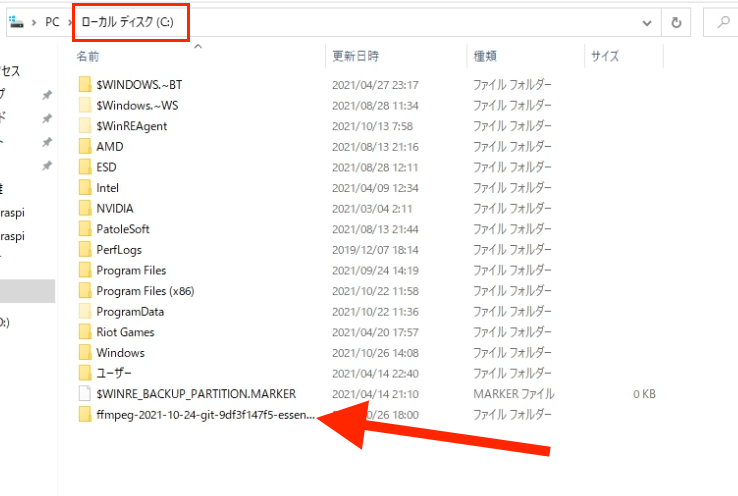
ダウンロードフォルダに置いたままだと削除してしまう可能性が高いので、わかりやすい、かつ、誤って削除することのないフォルダに移動させましょう。
今回は「C:」直下に移動させました。
Pathの追加
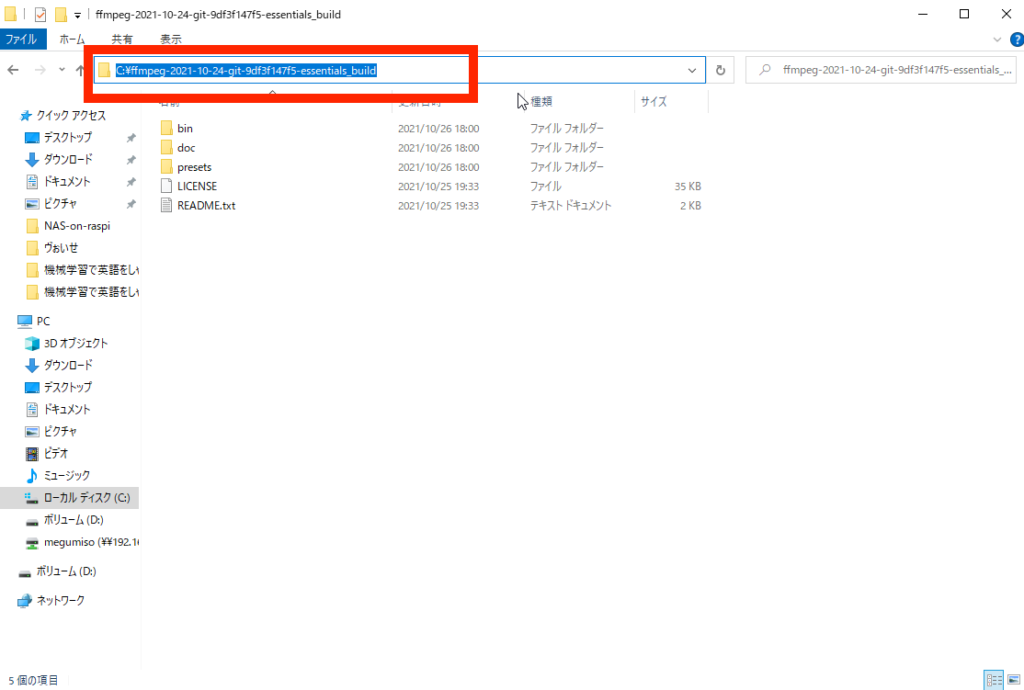
Pathを追加するには、追加する場所のディレクトリが必要になるので、あらかじめコピーしておきます。
赤枠の文字が書いていない部分をクリックすると、コピーができるようになるので、この部分をコピーします。
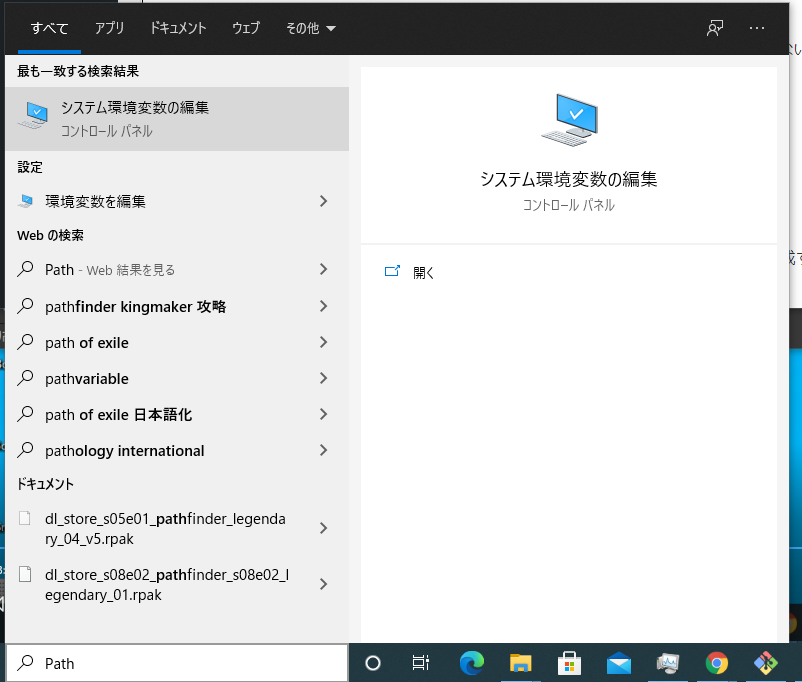
Windowsキーを押して、「Path」と検索すると、「システム環境変数の編集」がヒットするので、これを起動します。
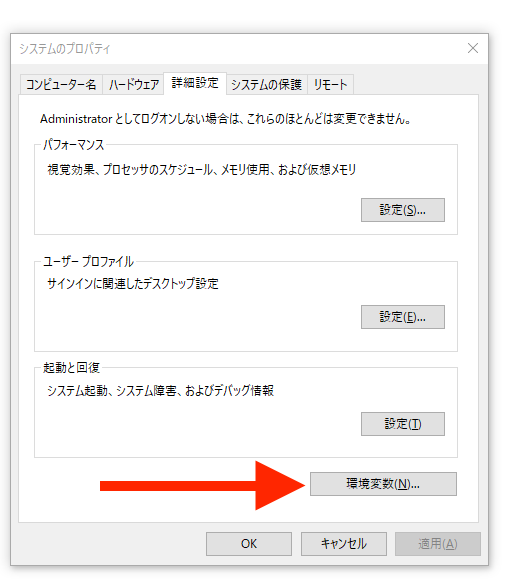
「環境変数」と書いてあるところをクリックします。
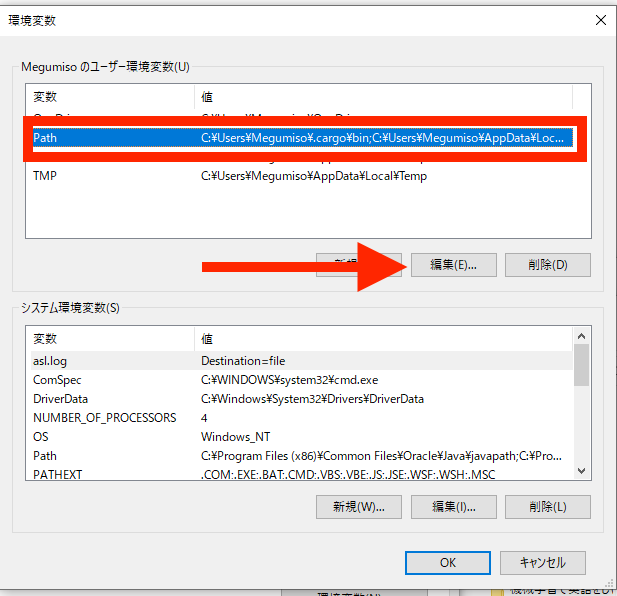
変数で「Path」と書いてあるところを選択して、「編集」をクリックします。
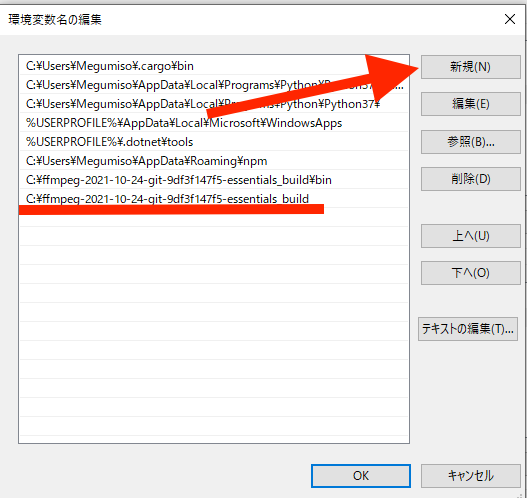
「新規」を選択して、出現した入力欄にコピーした内容をペーストします。
ペーストしたら最後に、「\bin」を追加してOKをクリックして完了です。
ここで間違っていると、Windowsが正常に動作しなくなったりするため、作業には十分注意してください。
Git
gitを扱うためのソフトです。 Windowsではgitを扱うためのツールが搭載されていないため、インストールが必要になります。
公式サイトからダウンロードしてきましょう。

「Download」ボタンを押すとすぐにダウンロードされます。
特に怪しいファイルが入ることはないので、インストーラーはすべてNextで問題ありません。
ツールダウンロード
今回はGitを使用してダウンロードします。
まずはGit Bashを起動します。

git clone https://github.com/CorentinJ/Real-Time-Voice-Cloning.gitこのコマンドを実行すると、ダウンロードが始まります。
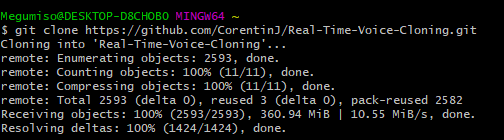
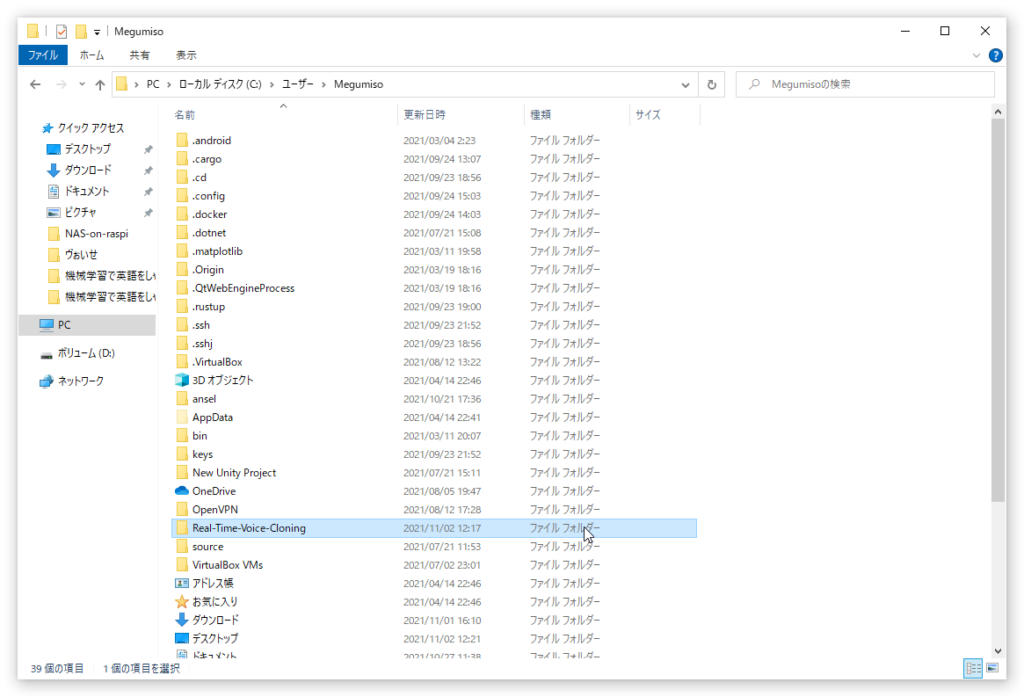
ダウンロードしたデータは、「C:\Users\<ユーザー名\Real-Time-Voice-Cloning」にほ損されます。
学習データの作成
機械学習なので、喋らせるための元になる声が必要になります。
なるべくデータが多ければ多いほど良いと思われるので、今回はラズパイでNASを作成する際の動画から音声だけを抽出したものを用意しました。
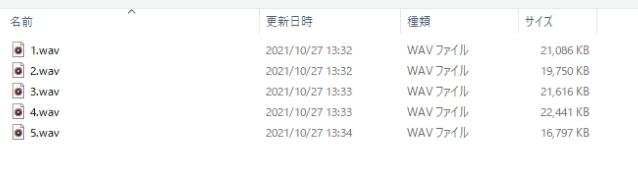
その音声を、このように5つに分けて読み込ませます。その理由は後述。
ツールの実行
今回使用するツールを実行してみましょう。
ツールはPythonを使用して作成されているため、コマンドから起動する必要があります。

python demo_toolbox.pyGitでダウンロードしたフォルダに移動して、このコマンドでツールを起動します。起動には少し時間がかかるので、気長に待ちましょう。
ちなみにcmdで利用するフォルダの移動は以下のコマンドで移動できます
cd <フォルダ名>先ほどの場所であれば、以下のコマンドですね。
cd C:\Users\<ユーザー名>\Real-Time-Voice-Cloning
起動すると、このような画面が現れます。
何やら難しそうですが、基本的にはデータの読み込み、セリフの入力と生成しか行わないので、実際に操作するボタンは3つだけになります。
学習データの読み込み
早速用意したゆっくりボイスを読み込ませてみましょう。

ここにあるボタンで学習データを読み込ませます。
データは複数あっても、なぜか1つずつしか読み込ませることができないので、ちまちま読み込ませていきます。

4つ読み込ませた段階で、このようなグラフが出現します。機械学習の指標だと思いますが、何を表しているのかはわかりません。
セリフの指定
右上でしゃべらせるセリフを指定できます。もちろん英語のみですが。
初期状態ではこのように入力されているので、このまま試していくことにします。
ボイス生成
設定はこれだけなので、いよいよボイスの生成をします。
セリフの下にある「Synthesize and vocode」ボタンでセリフの生成ができます。
生成されたボイスは、ぜひ動画でご覧ください!
まとめ
今回は機械学習を使ってゆっくりに英語を喋らせてみました。
創造よりもまったく違う声になったりして、とても楽しみながら動画と記事を作ることができました。
Geforceのグラボさえあれば誰でも利用できるので、記事を参考に使ってみてはいかがでしょうか。